o3 Deep Research Playground for Deep Research Evals
Use o3 for deep research: explore sources, synthesize findings, and compare quality vs other research models.
Bring your API keys. Pay once, use forever.






Best o3 Deep Research Playground
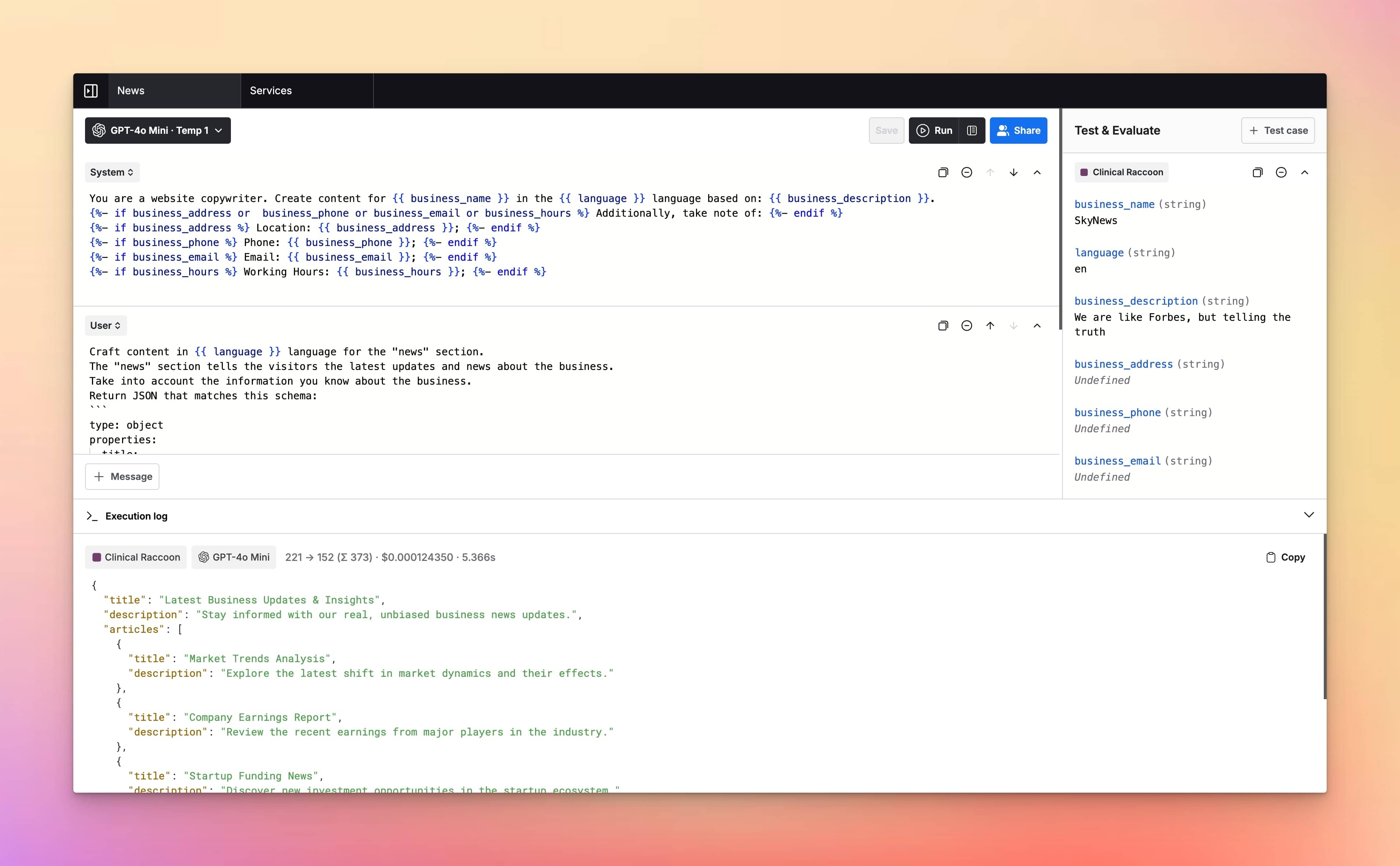
Run research workflows
Repeatable deep-research runs you can refine over time.
Compare results
Check coverage, structure, and usefulness side-by-side.
Use variables
Template research prompts and inputs for consistent evaluation.
Share & replay
Public links, transcripts, and export.
Private by default
We don’t train on your prompts and data.
Instant access
Bring your API keys. Start testing immediately.
Why Us over other LLM Playgrounds
Other playgroundsFrom VC-baked companies
o3 Deep Research PlaygroundPowered byLangFast
Explore All Features
Supported AI Models
- GPT-5
- GPT-5 Mini
- GPT-5 Nano
- GPT-5 Nano
- GPT-4.1
- GPT-4.1 Mini
- GPT-4.1 Nano
- GPT-4o
- GPT-4o Mini
- O1
- O1 Mini
- O3
- O3 Mini
- O4 Mini
- GPT-4 Turbo
- GPT-3.5 Turbo
- Claude AI Models (soon)
- Gemini AI Models (soon)
- Model Fine-tuning (soon)
Model configuration
- Custom System Instructions
- Reasoning Effort Control
- Stream Response Control
- Temperature Control
- Presence & Frequency Penalty
User Interface
- Customizable Workspace
- Wide Screen Support
- Hotkey & Shortcuts
- Voice Input (soon)
- Text-to-Speech (soon)
Playground Experience
- Prompt Library
- Prompt Templates & Variables
- Jinja2 Templates Support
- Upload Documents (soon)
- Language Output Control
- Parallel Chat Support
Prompt Management
- Prompt Folders
- Edit & Fork Prompts
- Prompt Versioning
- Upload Documents (soon)
- Share Prompts
Cost & Performance
- Cost estimation
- Token usage tracking
- Context length indicator
- Max token settings
Security and Privacy
- Private by Default
- API Tokens Cost Estimation
- No chats used for training
- Web Search & Live Data (soon)
Integrations
Plugins
- Custom Plugins (soon)
- Image search plugin (soon)
- Dall-E 3 (soon)
- Web page reader (soon)
Meet LangFast users
LangFast empowers hundreds of people to test and iterate on their prompts faster.






Frequently Asked Questions
What is a o3 Deep Research Playground for Deep Research Evals deep research playground?
A o3 Deep Research Playground for Deep Research Evals deep research playground is a UI for prompt testing and evals on research-style tasks—structured prompts, repeatable runs, and comparisons against other models.
What is this page optimized for?
Evaluating research behavior: coverage, structure, reasoning quality, and consistency across repeated runs—without building a research pipeline first.
Do I need an API key?
Yes. Bring your API keys. LangFast routes requests through our proxy.
Why require signup?
To prevent abuse, keep free limits fair, and let you save research runs, reuse prompt sets, and share results with collaborators.
What should I evaluate for deep research?
Coverage (did it miss key angles?), structure (outline quality), faithfulness to constraints, and how reliably it follows your requested format.
How do I evaluate consistency?
Rerun the same research brief multiple times and compare: do the main claims drift, does structure collapse, do key sections disappear?
Can I use a rubric for evaluation?
Yes. Define criteria like “coverage, specificity, actionability, clarity” and score outputs consistently across runs and models.
Can I compare o3 Deep Research Playground for Deep Research Evals with other models?
Yes. Run the same brief side-by-side to decide if deeper output quality is worth the extra cost/latency.
Can I test “research to deliverable” formats?
Yes. Evaluate outputs as memos, PRDs, competitive analyses, briefs, checklists, or structured tables—whatever you need to ship.
Can I test citation discipline?
If your workflow requires citations, add explicit constraints and test whether the model follows them consistently (and how it behaves when uncertain).
Can I run regression tests?
Yes. Save a research prompt set and rerun it after model changes or prompt edits to detect regressions in coverage and structure.
Can I use variables/templates for realistic briefs?
Yes. Inject product context, customer segments, constraints, and real inputs to make research prompts production-like.
Can I export requests for engineering or automation later?
Yes—export to cURL/JS/JSON so the exact call can be reproduced programmatically.
Can I share research results?
Yes. Share links for review, edits, or stakeholder alignment.
Is it free?
LangFast is free to use with some basic features. You need to provide your own API keys to run models and use the app. When you add your API keys, you pay the model provider (e.g., OpenAI) for the credits/tokens you use. LangFast premium features can be unlocked with a one-time purchase.
What happens when I hit limits?
Wait for the reset or add paid usage to keep running research evaluations.
How fast is it?
We stream responses through a lightweight proxy. Research tasks vary by model and load; compare latency across models directly.
Do you train on my prompts or research data?
No. We don’t train on your prompts or data. Sharing is opt-in and retention is configurable.
Where is my data processed?
Requests route to model providers. See the Data & Privacy page for processing regions and details.
How does this compare to LangChain?
LangChain is for building research agents and pipelines. LangFast is for testing research prompts and evaluating outputs before you build automation.
How does this compare to Langfuse, Basalt, or PromptLayer?
Those tools help manage datasets, tracing, and evals in workflows. LangFast is a fast interactive bench to compare research outputs and pick prompts/models first.