o4 Mini Playground for Prompt Testing
Test prompts on o4-mini, compare outputs/cost/latency across models, and iterate quickly without switching tools.
Bring your API keys. Pay once, use forever.






Best o4 Mini Playground
Start instantly
Bring your API keys. Just type and run.
Compare outputs
Side-by-side across multiple model providers.
Test with variables
Jinja2 inputs for repeatable checks.
Evaluate reliably
Spot inconsistency, format breaks, and failure modes.
Share & replay
Links, transcripts, and export.
Private by default
We don’t train on your prompts and data.
Why Us over other LLM Playgrounds
Other playgroundsFrom VC-baked companies
o4 Mini PlaygroundPowered byLangFast
Explore All Features
Supported AI Models
- GPT-5
- GPT-5 Mini
- GPT-5 Nano
- GPT-5 Nano
- GPT-4.1
- GPT-4.1 Mini
- GPT-4.1 Nano
- GPT-4o
- GPT-4o Mini
- O1
- O1 Mini
- O3
- O3 Mini
- O4 Mini
- GPT-4 Turbo
- GPT-3.5 Turbo
- Claude AI Models (soon)
- Gemini AI Models (soon)
- Model Fine-tuning (soon)
Model configuration
- Custom System Instructions
- Reasoning Effort Control
- Stream Response Control
- Temperature Control
- Presence & Frequency Penalty
User Interface
- Customizable Workspace
- Wide Screen Support
- Hotkey & Shortcuts
- Voice Input (soon)
- Text-to-Speech (soon)
Playground Experience
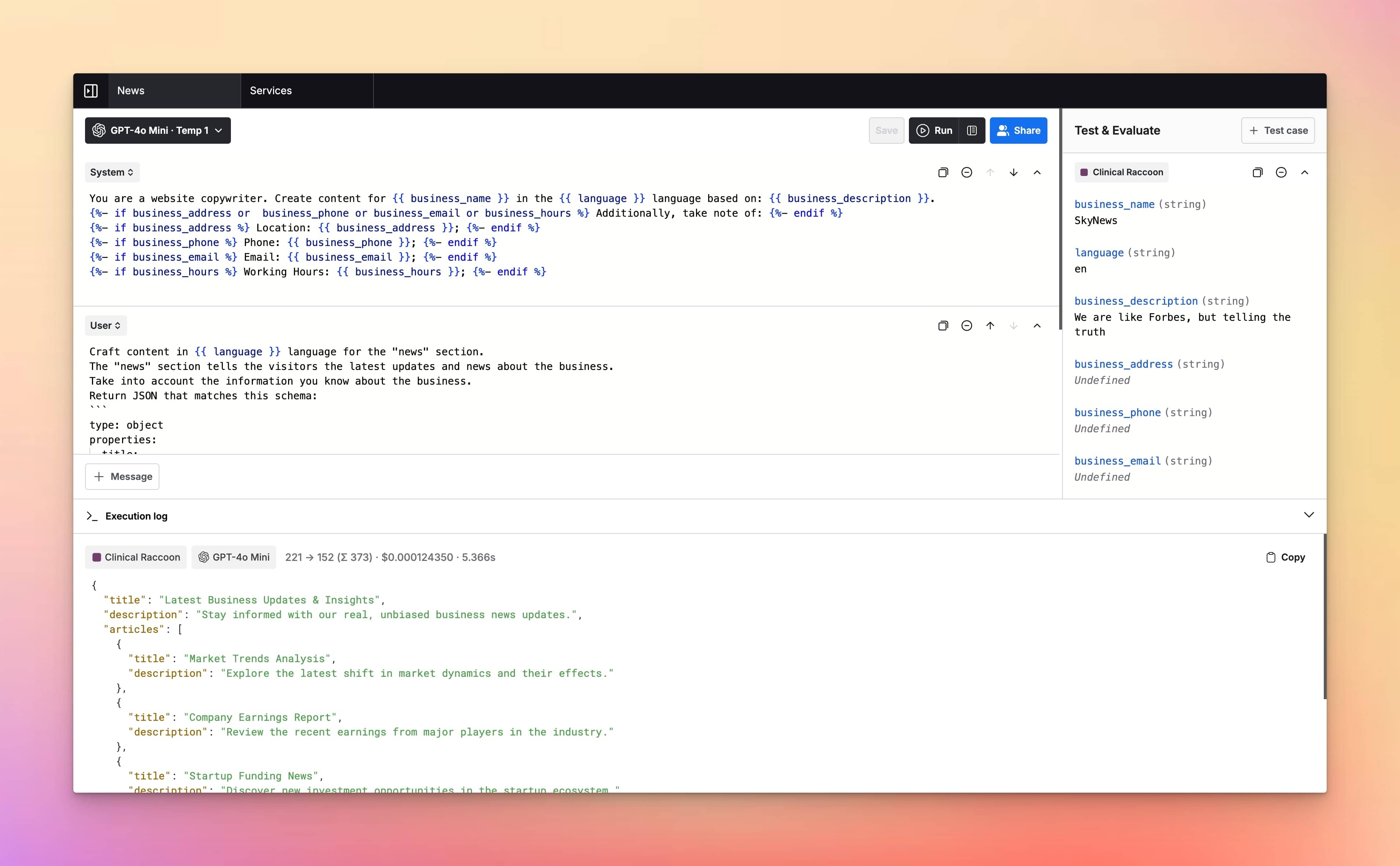
- Prompt Library
- Prompt Templates & Variables
- Jinja2 Templates Support
- Upload Documents (soon)
- Language Output Control
- Parallel Chat Support
Prompt Management
- Prompt Folders
- Edit & Fork Prompts
- Prompt Versioning
- Upload Documents (soon)
- Share Prompts
Cost & Performance
- Cost estimation
- Token usage tracking
- Context length indicator
- Max token settings
Security and Privacy
- Private by Default
- API Tokens Cost Estimation
- No chats used for training
- Web Search & Live Data (soon)
Integrations
Plugins
- Custom Plugins (soon)
- Image search plugin (soon)
- Dall-E 3 (soon)
- Web page reader (soon)
Meet LangFast users
LangFast empowers hundreds of people to test and iterate on their prompts faster.






Frequently Asked Questions
What is the o4 Mini playground?
The o4 Mini playground is a focused UI for prompt testing and quick eval-style checks on o4 Mini—so you can validate behavior before writing integration code.
What is this page designed to help me decide?
Whether o4 Mini is the right choice for your use case: quality vs cost, stability vs speed, and how it behaves on your real prompts and edge cases.
Do I need my own API keys?
Yes. Bring your API keys. LangFast handles routing.
Why do you require signup?
To keep the playground usable (rate limits + abuse prevention) and to enable saved runs, sharing, and team-friendly history.
What kinds of prompt evaluations can I do here?
Regression tests, rubric scoring, style/format compliance, refusal behavior checks, and “must-pass” prompts that shouldn’t degrade over time.
Can I run repeatable tests instead of one-off prompts?
Yes. Save a prompt set, re-run it after changes, and compare outputs across runs to spot regressions.
Can I compare o4 Mini to other models?
Yes. Run the same prompt set side-by-side across providers and choose the best model for your constraints.
Can I export requests for engineering handoff?
Yes—export cURL/JS/JSON so engineers can reproduce exactly, including parameters and prompt content.
Can I share results with my team or stakeholders?
Yes. Share links for review, approval, or to align on what “good” looks like before you ship.
Is it free?
LangFast is free to use with some basic features. You need to provide your own API keys to run models and use the app. When you add your API keys, you pay the model provider (e.g., OpenAI) for the credits/tokens you use. LangFast premium features can be unlocked with a one-time purchase.
How does pricing work when I scale up?
Usage-based: you add volume when you need it. This is designed for startups and small teams who don’t want enterprise plans.
How fast is it?
We stream responses through a lightweight proxy. Actual speed depends on o4 Mini and current load; you can compare latency across models directly.
What’s the context window and limits?
It varies by model. We show key limits (like context window) next to o4 Mini in the model picker.
Can I use variables / templates for real-world prompts?
Yes. Inject structured inputs (customer data, tickets, policies, product specs) to test prompts against realistic cases.
Can I test structured output formats?
Yes. Validate JSON/schema compliance, headings, tables, and other formatting requirements as part of your eval prompts.
Do you train on my prompts and data?
No. We don’t train on your prompts. Sharing is opt-in, and retention is configurable.
Where is my data processed?
Requests route to model providers. See the Data & Privacy page for region and processing details.
Can I use outputs commercially?
Usually yes, subject to each provider’s terms. We link to terms from the model picker.
How does this compare to LangChain?
LangChain helps you build apps/agents. LangFast helps you decide prompts and models first, without building any pipeline.
How does this compare to Langfuse, Basalt, or PromptLayer?
Those tools are for tracing, datasets, and eval management in production workflows. LangFast is the quickest way to run prompt tests and comparisons interactively.